slow feature learning
I worked with Western Washington University professor Dr. Kameron Harris on a machine learning research project in his university ran Glomerulus Lab.
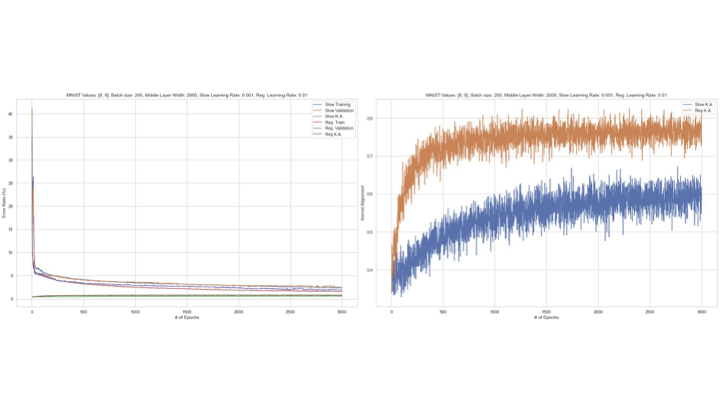
CKA and Differing Learning Rates
My project was labeled “Slow Feature Learning” and primarily entailed an exploration of a model comparison technique called Centered Kernel Alignment, using a single hidden layer neural network with different converging learning rates. Each model was trained on a binary digit pair from the MNist dataset.
Most commonly CKA is used as a comparison measure between two different neural networks. However, in our research we compare the model with the data it is trained on. More on CKA can be found in the paper link by S. Kornblith, et al. This type of comparison can be done by using the model feature map $\phi$ and the dataset target vector $y$
One result was we found NNs with smaller readout learning rates tended to have a lower total CKA.
Performance Optimization
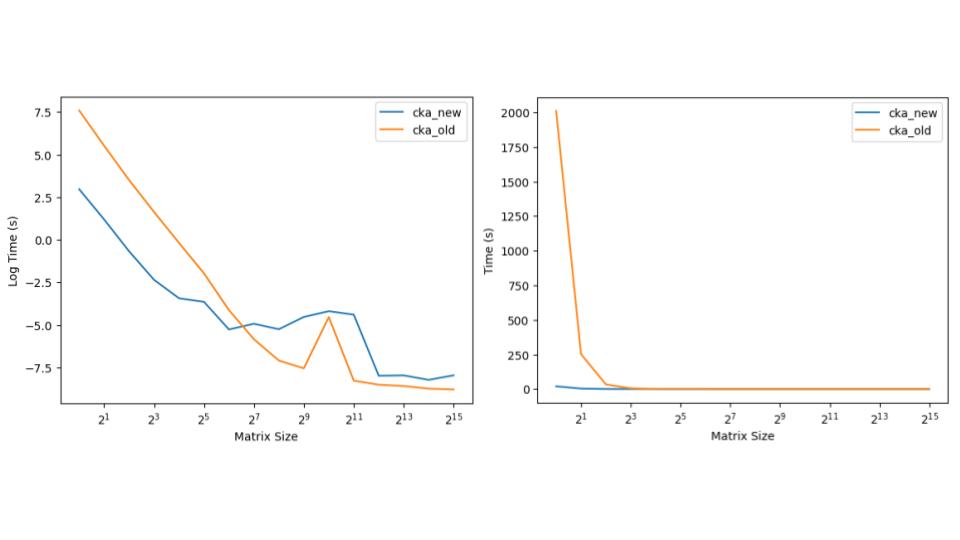
An aspect of the project that I found particularly interesting was performance optimization. Historically calculating CKA can be computationally expensive as it requires taking the outer product of a potentially very-large vector. This became a problem for us when we decided to calculate the CKA of each digit pair over a series of differing learning rates (causing for 67500 calculations). At an average time of 173.02s for each CKA (per our machines) it would end up costing us 135 days to calculate on one machine.
This led us to consider some mathematical tricks to optimize our program. We were able to optimize the CKA function to run for an average 0.7731s for our sized matrices. That improvement alone allows us to calculate the CKA for all models in just 14.5 hr. The following is a chart showing the improvement we made in calculating the CKA over a growing matrix space.
Out of curiosity I decided to bring the optimization a step further with an experiment in CUDA C++ programming. Using the optimized model while on the same hardware, I achieved a CKA calculation time of 0.082s for our sized matrix. Unfortunately, the CDUA C++ model was unable to be used for the final calculation due to the GPU cluster at our university having outdated NVIDIA software. Below is the PyTorch model written in CUDA C++.
class NN : public torch::nn::Module {
public:
NN(int input_size = 784, int middle_width = 2048, int num_classes = 2) {
features_ = register_module("features", torch::nn::Sequential(
torch::nn::Linear(input_size, middle_width),
torch::nn::ReLU()
));
readout_ = register_module("readout", torch::nn::Linear(middle_width, num_classes));
}
torch::Tensor forward(torch::Tensor x) {
x = features_->forward(x);
x = readout_->forward(x);
return x;
}
private:
torch::nn::Sequential features_;
torch::nn::Linear readout_;
};
Final Thanks
Finally, this project meant a lot to me as it was my first experience with academic research. I owe a huge debt to Kameron Harris for letting me join the group early in my college career. If you care to check out the lab for similar work please check on the Glomerulus Lab Webpage.