climate visual transformer
For my final project in my CSCI481 (Deep Learning) course at Western Washington University: I aimed to localize weather patterns in time using a grid map of daily-mean temperatures across the globe for every day in the year.
The given dataset consisted of global temperature maps with daily-mean temperatures (measured in Kelvin) across a years time, of which there were 659 samples (note: for anonymity the exact dataset was kept secret). Each datapoint was of the size [128, 256] correlating to [latitude/height, longitude/width]. Finally, the task was to predict the starting date, disregarding year, of a given 7-day sequence of data.
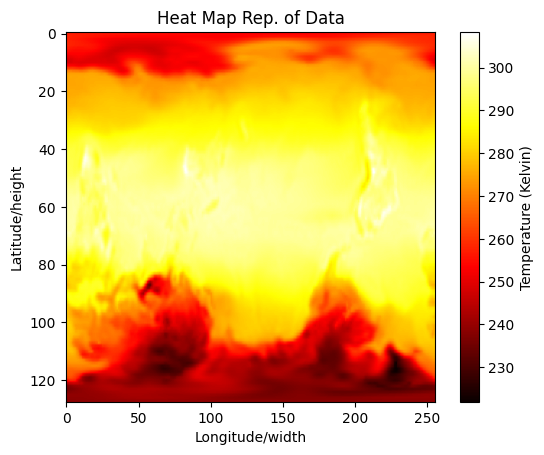
For the model I chose to attempt solving the task while using my own architectured ViT. At the time of this project visual transformers were still new technology and not yet built into popular machine learning frameworks such as Pytorch and Tensorflow. This led me to architect my own ViT model based on the source code available from “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”, Dosovitskiy et al. (2020). However, considerable alteration had to be made to support a 10gb v-ram limitation and to account for temporal dependencies in the data.
class VisionTransformer(nn.Module):
""" ViT implementation; note this is a very oversimplified version which
should be fine for the Climate Dataset.
:param img_size: size of the image (height x weight)
:param patch_size: size of the patch (height x weight)
:param input_channels: number of channels, should be 1
:param num_classes: number of classes, should be 358
:param embed_dim: dimensionality of the token/patch embeddings
:param depth: number of blocks
:param num_heads: number of attention heads
:param hidden_layer_ratio: determines the hidden dim for the MLP
:param qkv_bias: includes bias to the qkv
:param p: dropout probability
:param attn_p: dropout probability
"""
def __init__(
self,
img_size: (int, int) = (128, 256),
patch_size: (int, int) = (8, 8),
input_channels: int = 1,
num_classes: int = 358,
embed_dim: int = 768,
num_frames: int = 8,
depth=12,
num_heads=12,
hidden_layer_ratio=4.,
qkv_bias=True,
p=0.,
attn_p=0.,
):
super().__init__()
self.patch_embed = PatchEmbed(
img_size=img_size,
patch_size=patch_size,
num_frames=num_frames,
input_channels=input_channels,
embed_dim=embed_dim,
)
self.cls_token = nn.Parameter(torch.zeros(1, num_frames, 1, embed_dim))
self.pos_embed = nn.Parameter(
torch.zeros(1, num_frames, 1 + self.patch_embed.n_patches, embed_dim)
)
self.pos_drop = nn.Dropout(p=p)
self.blocks = nn.ModuleList(
[
Block(
dim=embed_dim,
num_heads=num_heads,
hidden_layer_ratio=hidden_layer_ratio,
qkv_bias=qkv_bias,
p=p,
attn_p=attn_p,
)
for _ in range(depth)
]
)
self.norm = nn.LayerNorm(embed_dim, eps=1e-6)
self.head = nn.Linear(embed_dim, 2)
def forward(self, x: torch.Tensor) -> torch.Tensor:
""" Run the forward pass for the transformer.
:param x: (batch_size, num_frames, input_channels, img_height, img_width)
:return x: (batch_size)
"""
batch_size, num_frames = x.shape[:2]
x = self.patch_embed(x) # (batch_size, num_frames, num_patches, embed_dim)
cls_token = self.cls_token.expand(
batch_size, num_frames, -1, -1
) # (batch_size, num_frames, 1, embed_dim)
x = torch.cat((cls_token, x), dim=2) # (batch_size, num_frames, 1 + n_patches, embed_dim)
x = x + self.pos_embed # (batch_size, num_frames, 1 + n_patches, embed_dim)
x = self.pos_drop(x)
outputs = []
for frame in range(num_frames):
input_frame = x[:, frame, :]
for block in self.blocks:
input_frame = block(input_frame)
output_frame = self.norm(input_frame)
cls_token_frame = output_frame[:, 0]
output_frame = self.head(cls_token_frame)
outputs.append(output_frame)
x = torch.stack(outputs, dim=1)
x = x.mean(dim=1)
return x
A fascinating benefit of the ViT model was we could easily convert it to predict for either classification or regression. Classification required taking each day (0…364) as its own class. Regression was a bit more tricky. To handle the cyclical nature of data I mapped the year around the unit circle, such that each day correlated to every 1/365th point. Then the model would predict the Cartesian (x,y) coordinates for every feature.
Using limited resources, i.e. Nvidia 2080 GPUs I was able to achieve the following performance.
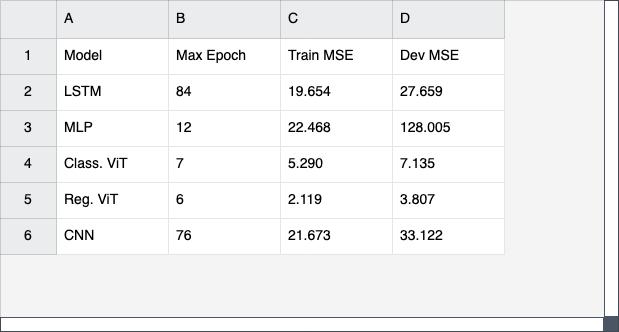
Considering the heavy computation limitation, and the natural tendencies for ViT models to become significantly more performant as their complexity increases, I suspect that given more computational power we would see significantly better performance.